Machine Learning Terminology
Intro
Here we will note some common terminology used in the fields of Artificial Intelligence and Machine Learning.
Parameters vs Hyperparameters
There is a key difference between hyperparameters and parameters.
Hyperparameters are values set prior to the training process, such as number of neurons, layers, learning rate etc. Selecting the best hyperparameter values (via optimization) is an extremely challenging task.
Parameter values that are obtained by the training process such as network weights and biases.

We are attempting to find the global minimum, however there are several pitfalls such as arriving at a local minimum or overshooting the global minimum by using a large learning rate, speeding up the optimization process but never achieving the true minimum.
Gradient Descent Algorithm
Gradient descent is an optimization algorithm used to obtain the optimized network weight and bias values.
It works by iteratively trying to minimize the cost function.
It works by calculating the gradient of the cost function and moving in the negative direction until the local/global minimum is achieved
If the positive of the gradient is taken, local/global maximum is achieved

Learning Rate
- The size of the steps taken are called the learning rate
- If learning rate increases, the area covered in the search space will increase so we might reach global minimum faster
- However, we can overshoot the target
- For small learning rates, training will take much longer to reach optimized weight values
Back Propagation
Back Propagation is a method used to train Artificial Neural Networks by calculating the gradient needed to update network weights.
It is commonly used by the gradient descent optimization algorithm to adjust the weight of neurons by calculating the gradient of the loss function.
L1 & L2 Regularization
Essentially these are methods of smoothing out over-fit polynomial regression lines
L1 Regularization: Used to perform feature selection so some features are allowed to go to zero. If you believe that some feature are not important and you can afford to lose them, then L1 regularization is a good choice. The output might become sparse since some features might have been removed.
L2 Regularization All features are maintained, but weighted accordingly. No features are allowed to go to zero. If you believe that all features are important and you'd like to keep them but weigh them accordingly.
Boosting
Boosting works by learning from previous mistakes (errors in model predictions) to come up with better future predictions.
Boosting is an ensemble machine learning technique that works by training weak models in a sequential fashion.
Each model is trying to learn from the previous weak model and become better at making predictions.
Boosting algorithms work by building a model from the training data, then the second model is built based on the mistakes (residuals) of the first model. The algorithm repeats until the maximum number of models have been created or until the model provides good predictions.
Decision Trees
Decision Trees are a supervised Machine Learning technique where data is split according to a certain condition/parameter.
The tree consists of decision nodes and leaves
- Leaves are the decisions or the final outcomes
- Decision nodes are where the data is split based on a certain attribute
The tree ensemble model consists of a set of classification and regression trees (CART)
A CART that classifies whether an individual will like a computer game X or not is shown below
Members of the family are divided into leaves and a score is assigned to each leaf.
XGBoost
XGBoost or Extreme Gradient Boosting is the algorithm of choice for many data scientists and could be used for regression and classification tasks.
XGBoost is a supervised learning algorithm and implements gradient boosted trees algorithm.
The algorithm works by combining an ensemble of predictions from several weak models.
It is robust to many data distributions and relationships and offers many hyperparameters to tune model performance.
XGBoost offers increased speed and enhanced memory utilization.
XGBoost is analogous to the idea of "discovering truth by building on previous discoveries".
Advantages
- No need to perform any feature scaling
- Can work well with missing data
- Robust to outliers in the data
- Can work well for both regression and classification
- Computationally efficient and produces fast predictions
- Works with distributed training: AWS can distribute the training process and data on many machines
Disadvantages
- Poor extrapolation characteristics
- Need extensive tuning
- Slow training
Hyperparameters
There are over 40 hyperparameters to tune XGBoost within AWS SageMaker. Here are the most important ones
Max_depth (0-inf): is critical to ensure that you have the right balance between bias and variance. If the max-depth is set too small, you will underfit the training data. If you increase the max-depth, the model will become more complex and will overfit the training data. Default value is 6.
Gamma (0-inf): Minimum loss reduction needed to add more partitions to the tree.
Eta (0-1): Step size shrinkage used in update to prevent overfitting and make the boosting process more conservative. After each boosting step, you can directly get the weights of new features, and eta shrinks the feature weights.
Alpha: L1 regularization term on weights. Regularization term to avoid overfitting. The higher the gamma the higher the regularization. If gamma is set to zero, no regularization is put in place.
Lambda: L2 regularization
Supervised vs Unsupervised
In supervised machine learning we use training algorithms with labelled input/output data to achieve a classification (dog, cat, horse) or regression(linear prediction, such as predicted sales).
In unsupervised machine learning the training algorithms use unlabelled data and attempt to discover a pattern on their own. The end result will be a clustering of data.
Data
Machine learning models require data to train. There are generally two types of data that we could use to train machine learning models. Labelled or Unlabelled.
Sample Data Sources
UCI Machine Learning Repository
Unlabeled Dataset
Unlabeled data consists of data that does not have an explanation (class or tag) with it. Unlabelled datasets are used in unsupervised machine learning.
Labeled Dataset
Labeled data consists of unlabeled data but with a class or tag associated with it. Labelled datasets are used in supervised machine learning.
Good Data
- Many samples (large number of data points)
- Not biased
- Does not contain missing data points
- Only contains (relevant) important features
- Does not contain duplicate samples
Bad Data
- Few samples (small number of data points)
- Biased
- Contains missing data points
- Contains many irrelevant (useless) features
- Contains duplicate samples
Neural Network
A neural network is a subset of Machine Learning. It is a series of artificial neurons working together to reach a conclusion, such as a classification or linear equation. An individual neuron takes the following form:
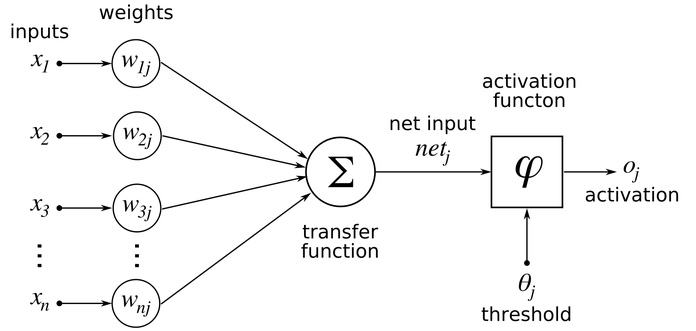
The transfer function could be for example a linear regression, or multiple linear regression.
Activation Functions
The activation function is a modifier that is added on the tail end of the transfer function. A simple example of an activation function could be a simple classifier function. For example it could be a simple threshhold at the number 42. Everything <=42 is set to 0 and everything >=42 is set to 1.
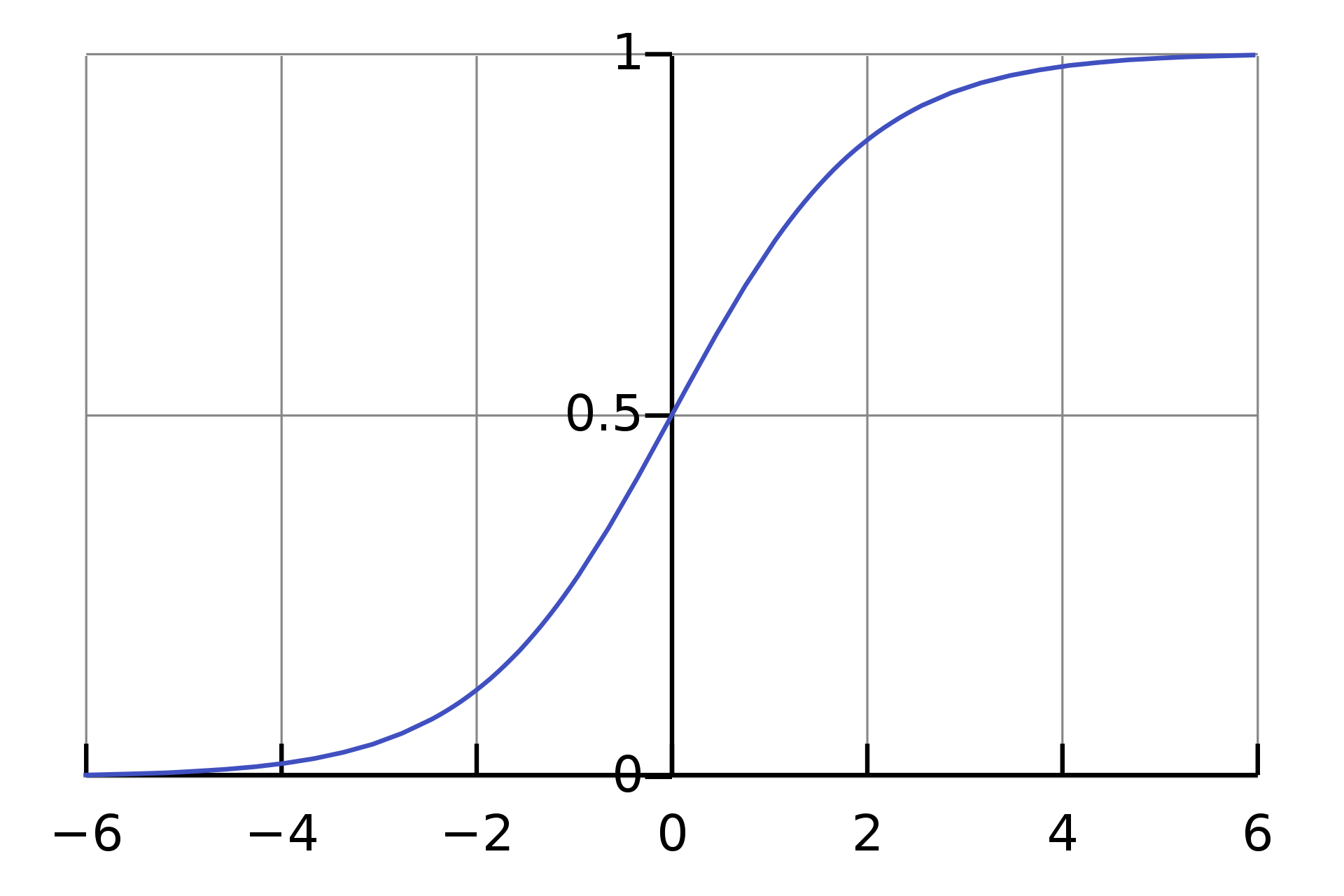
Sigmoid & Tanh Sigmoid
A sigmoid function is essentially a bounding function that takes outliers in a set and sets them equal to 0 or 1, or -1 and 1 (Tanh), while numbers within the "standard range" are given a value in between.
RELU
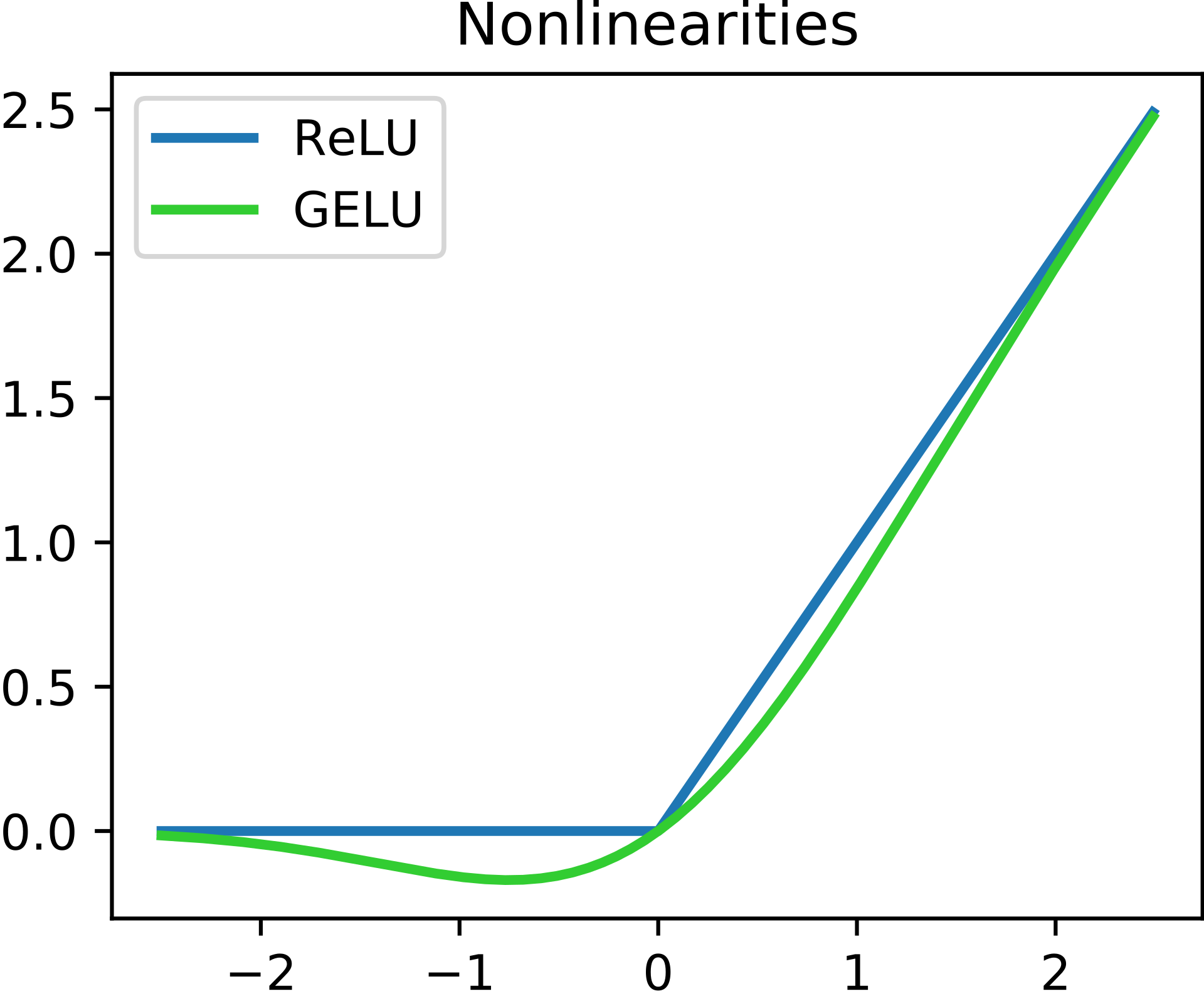
In short:
- If Input x < 0, output is 0 and if x > 0 the output is x
- Generally used in hidden layers
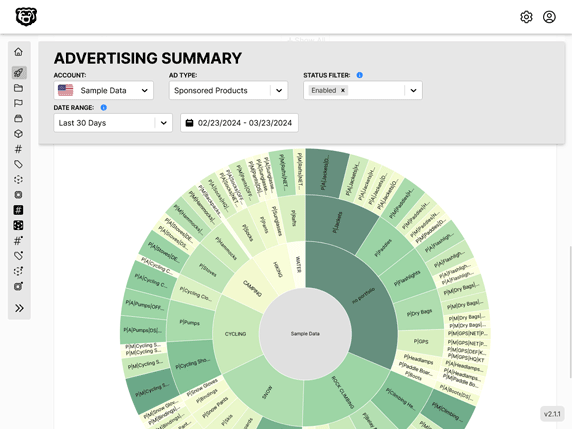
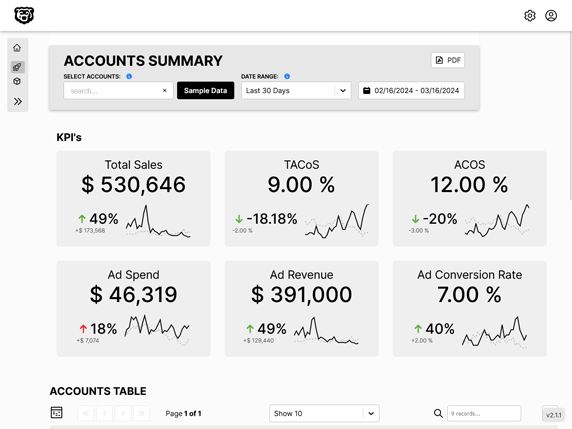
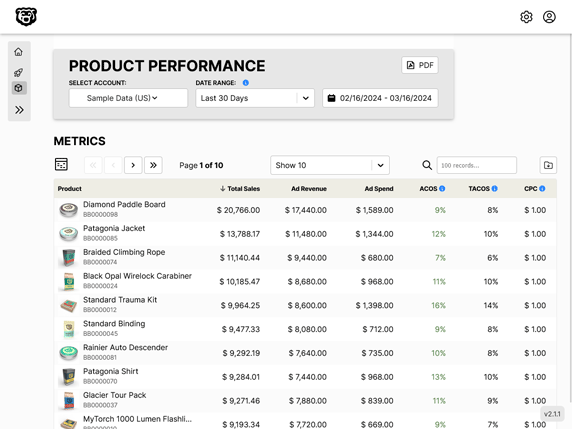
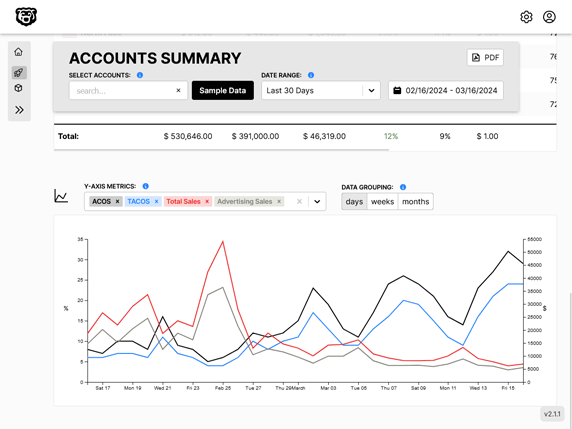
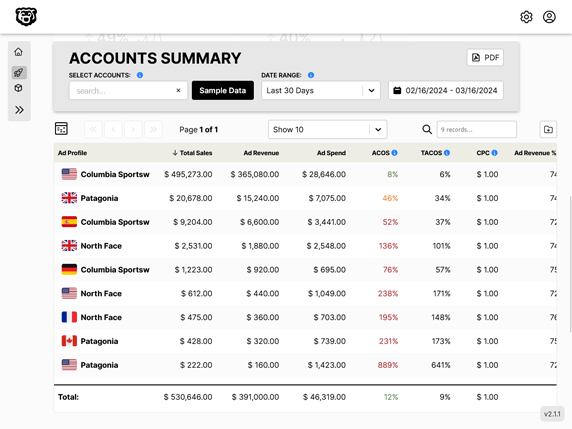
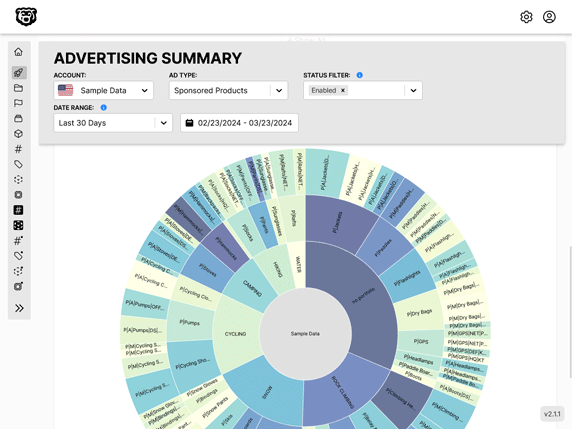
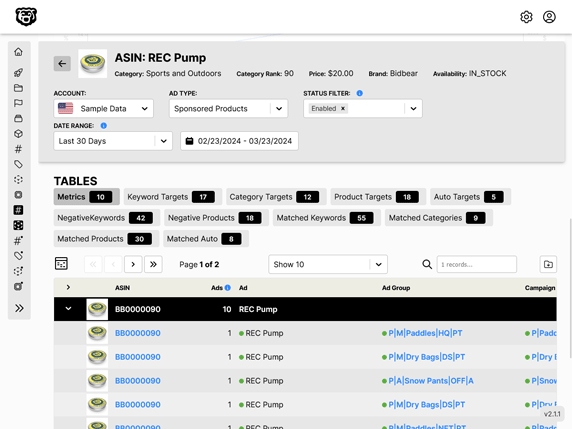
Automated Amazon Reports
Automatically download Amazon Seller and Advertising reports to a private database. View beautiful, on demand, exportable performance reports.