Gatsby: Sourcing Content From The File System
Intro
Eventually we will be bringing in our blog post content using a headless CMS, but for right now lets look at writing blog posts manually using Markdown and having Gatsby import those from the local filesystem.
File Structure
Inside the src directory we make another folder called posts and this is going to get filled with Markdown Files.

We can of course change this location. The location of the content to pull in is one of the options available to us in the config file, as we will see later.
Markdown Files
Gatsby converts these markdown files to pages. If you are unfamiliar with Markdown Syntax
Frontmatter
When you create a Markdown file, you can include a set of key value pairs that can be used to provide additional data relevant to specific pages in the GraphQL data layer. This data is called frontmatter and is denoted by the triple dashes at the start and end of the block. This block will be parsed by gatsby-transformer-remark as frontmatter. The GraphQL API will provide the key value pairs as data in your React components.
Get Markdown Files Into Gatsby
Once we throw a couple of sample MD files in there we can work on getting these files into Gatsby so that it can convert them to HTML.
Source Plugin
Step 1 is to tell Gatsby we are sourcing content from an external source, which as of right now is my file system. To accomplish that we are going to install another plugin called gatsby-source-filesystem. Then we have to actually configure this plugin a bit, which is covered in the docs but here is an example of a configuration in the gatsby-config.js file.
module.exports = {
siteMetadata: {
title: 'Gatsby Training',
author: 'Nick Coughlin'
},
plugins: [
'gatsby-plugin-sass',
{
resolve: 'gatsby-source-filesystem',
options: {
name: 'src',
path: `${__dirname}/src/`
}
}
],
}
GraphQL Query
Now that our source-filesystem plugin is installed, our local files should be available in GraphQL. If we open the playground and go to the docs we can see.
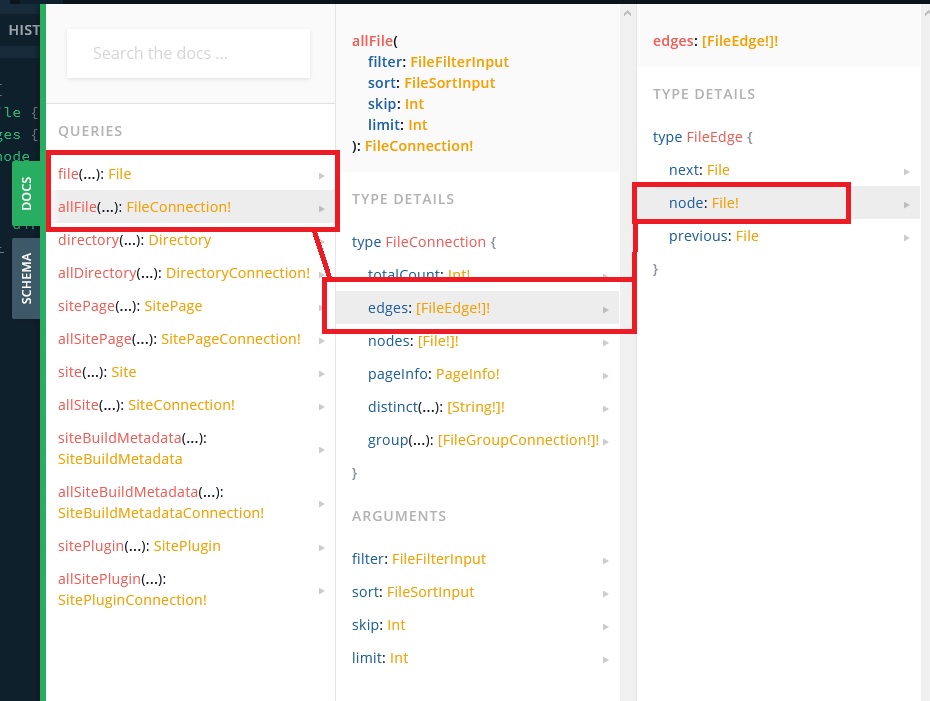
We now have access to two new endpoints, the file and allFile directories. Using the new directory allFiles we can create a query that shows all of the files in our project.
query {
allFile {
edges {
node {
name
extension
dir
}
}
}
}

And next we need to filter out the MD files and then convert them to HTML.
Transform Markdown
To transform the MD files we will be using a plugin called gatsby-transformer-remark. Once that has been installed and added to the gatsby-config file you will now have two more endpoints in the playground.
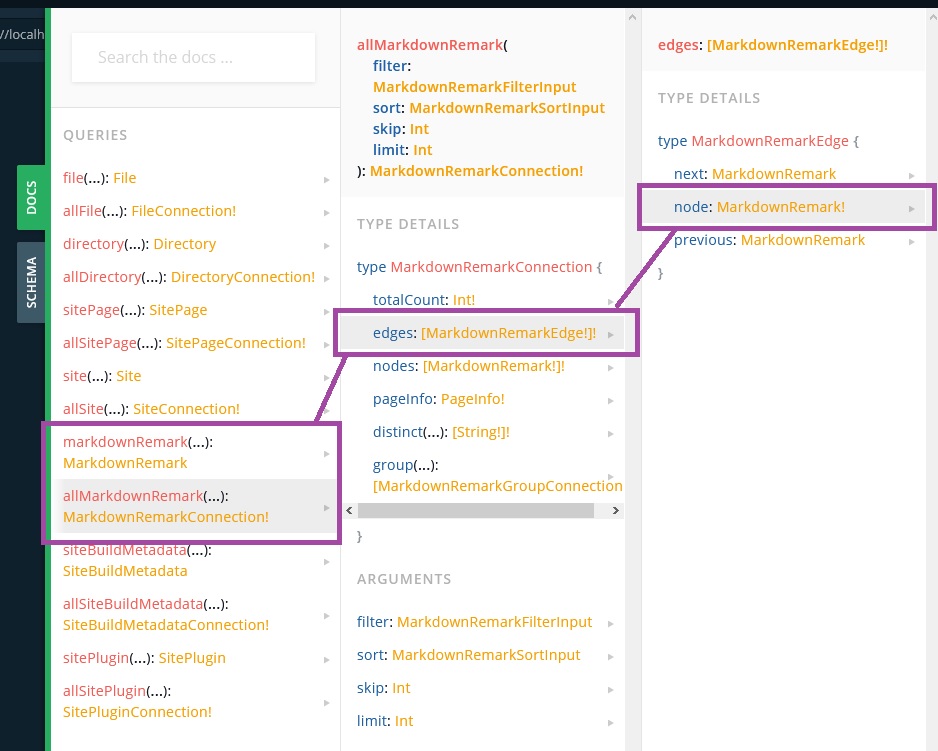
Which we can then use to construct a new query.
query {
allMarkdownRemark {
edges {
node {
frontmatter {
title
date
}
html
excerpt
wordCount{words}
}
}
}
}
And we can then see that pulls in the data we need to insert into a template to construct pages automatically.

We have a title, a date, the post contents in HTML format, a post excerpt and a word count .
Iterating Over API Data To List Blog Posts
This process will be incredibly similar to the process that we covered in our React post about looping over images returned from Unsplash API.
Here is our BlogPage component. In this component we just want to loop over the title and the date. The actual content will be on the individual post pages (which we are getting to). But this is going to be the blog index so the title and date are fine.
We start by making a helper variable called data and we set that equal to our GraphQL query. Then we loop over the returned object using map and create an li for every ‘edge’.
import React from "react"
import { graphql, useStaticQuery } from "gatsby"
import Layout from "../components/layout"
const BlogPage = () => {
const data = useStaticQuery(graphql`
query {
allMarkdownRemark {
edges {
node {
frontmatter {
title
date
}
}
}
}
}
`)
return (
<Layout>
<h1> Blog </h1>
<ul>
{data.allMarkdownRemark.edges.map(edge => {
return (
<li>
<h2>{edge.node.frontmatter.title}</h2>
<p>{edge.node.frontmatter.date}</p>
</li>
)
})}
</ul>
</Layout>
)
}
export default BlogPage
Note that we stop drilling into the query at edges. That is the point where every record becomes an individual. This seems like sort of an arbitrary name… edges. I like to think of it like I am rifling through a filing cabinet with my fingertips, we only touch the top edge of each folder, therefore each edge is an individual record.
GitHub Repo
Comments
Recent Work
Basalt
basalt.softwareFree desktop AI Chat client, designed for developers and businesses. Unlocks advanced model settings only available in the API. Includes quality of life features like custom syntax highlighting.
BidBear
bidbear.ioBidbear is a report automation tool. It downloads Amazon Seller and Advertising reports, daily, to a private database. It then merges and formats the data into beautiful, on demand, exportable performance reports.