AWS Scheduled Automations
Intro
According to Amazon: EventBridge is a serverless event bus service that helps connect external SaaS providers with your own applications and AWS services. EventBridge enables you to decouple your architectures to make it faster to build and innovate, using routing rules to deliver events to selected targets.
However not all of these events need to be triggered, they can easily be scheduled. For example, a daily event. I currently have a goal to schedule a daily event that makes API calls which return Gzipped files, which I would then like to save into a database. Should I then have a DynamoDB table to keep track of which API calls I would like to make along with the required credentials? What if I need to make hundreds of these API calls. It seems like some sort of queue would be in order. Let's briefly go over how to set a scheduled event in EventBridge, and then review our AWS service options to find the best one to handle this workflow.
Create a Scheduled Event
Inside EventBridge go to rules > create rule
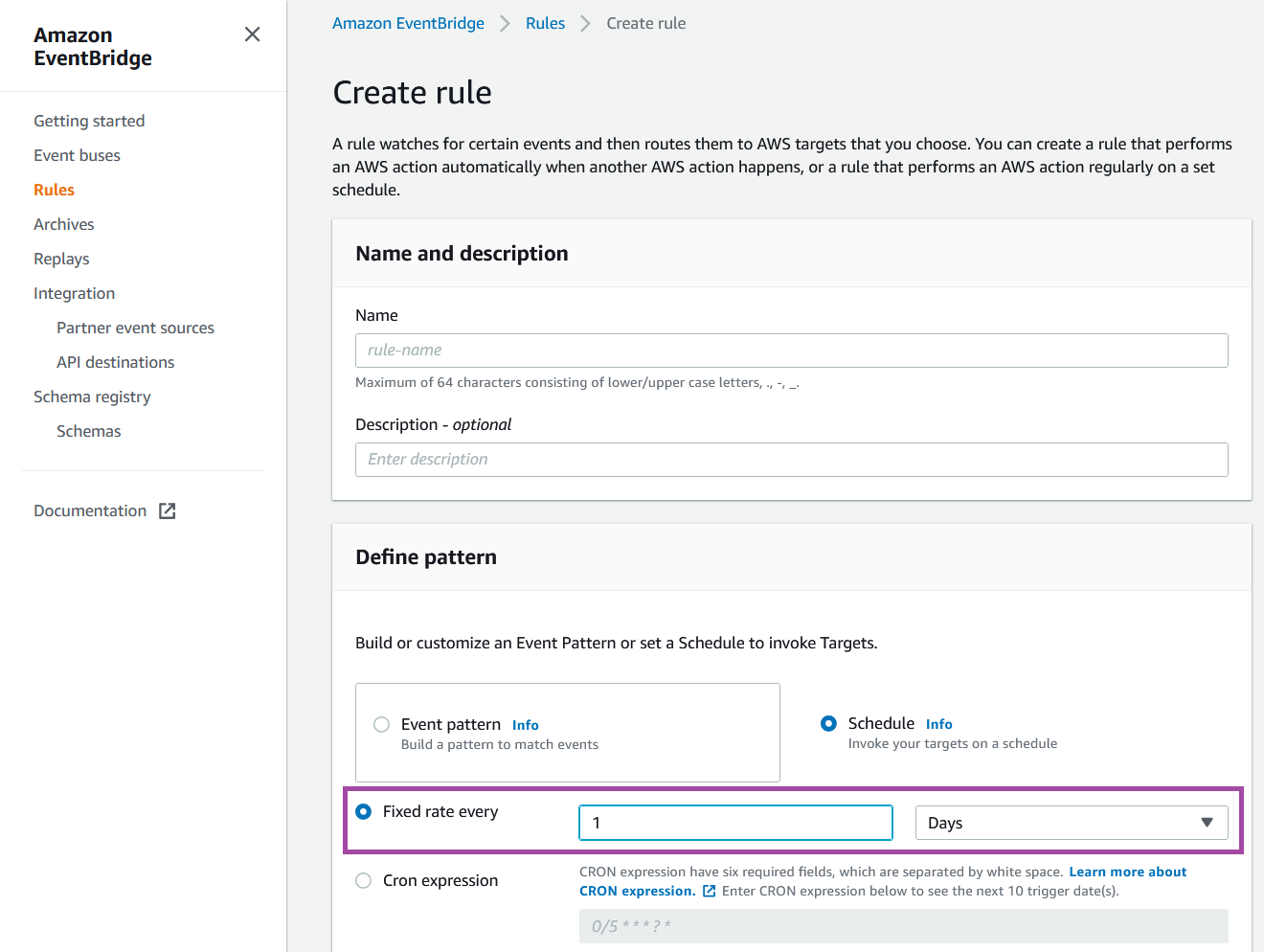
You can then name the rule and set it on a fixed schedule, or if you want something a little more complicated (IE every other thursday @ noon) you can use a cron expression.
This is where it gets interesting, we can select the event target, for example a Lambda function.
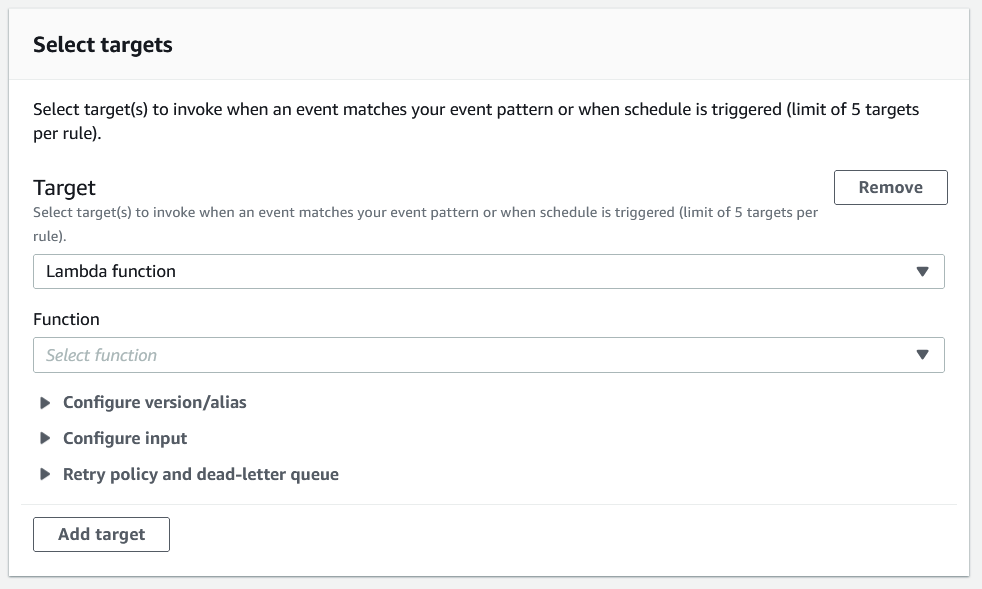
Event Targets
There are a lot of choices here. For our purposes i'm going to look at the following.
- Lambda
- AWS Batch (job queue)
- Step Functions (state machine)
- Glue (workflow)
- Kinesis (stream)
- Redshift (cluster)
- Sagemaker Pipeline
- SQS (queue)
Lambda
Lambda I am already very familiar with, we know for certain that Lambda could handle a lot of this. The question really is if any of these other services can do the job of Lambda here in a better/easier/dedicated way. So let's explore that.
AWS Batch (job queue)
Batch will automatically provision a set of resources to run large scale compute jobs synchronously. It looks like this is what we would use if we needed to train several machine learning models simultaneously. Which we may...
Step Functions (state machine)
It looks like this is going to need a whole post, but this could be very useful. It's a GUI based system for complex state based functions. IE we could do different things depending on how our API call was returned, and plan out multiple steps clearly. Going to dig into this.

Glue (workflow)
AWS Glue is a fully managed ETL (extract, transform and load) service that makes it simple to categorize your data, clean it, enrich it and move it reliably between various data stores.
So it sounds like this is the service that we are going to use once our data has been downloaded from the API and successfully saved into an S3 Bucket, we can extract it, clean it and transform it in the way that we need before feeding it into a machine learning model endpoint, and then back to S3 or DynamoDB again.
With Glue we will set up crawlers to define our data locations, and then workflows (which we can use Glue Databrew to help create) which are written with spark scripts, to transform the data and place it in a destination bucket. And we can use these workflows as steps in our Step Functions.
Kinesis (stream)
Kinesis is for streaming data, which I don't believe I have a use case for right now.
Redshift (cluster)
Seems like this is a cluster of databases for managing massive databases. Doesn't seem like I need this yet, but we will see. Also can get very expensive very quickly...
SageMaker Pipeline
If we wanted to create a new machine learning model for each customer, instead of creating one model and feeding all the data through that endpoint, we could create a Sagemaker Pipeline, which is a sort of CI/CD for machine learning models. Automating the process of creating models based on a template.
SQS (queue)
In short this is a queuing system that is designed to mitigate high volume request spikes, such as read/write operations to a DynamoDB faster than the rate limit allows. This doesn't seem like something that I will be running into anytime soon, so i'm going to categorize this as a possible problem for "future me".
Conclusion
My takeaway from this is that I should actually be at step functions to help me manage some of the more complex operations and orchestrate the use of my microservices. This will also give me increased re-usability of my Lambda functions, like the one that refreshes the authorization token for the API.
Comments
Recent Work
Basalt
basalt.softwareFree desktop AI Chat client, designed for developers and businesses. Unlocks advanced model settings only available in the API. Includes quality of life features like custom syntax highlighting.
BidBear
bidbear.ioBidbear is a report automation tool. It downloads Amazon Seller and Advertising reports, daily, to a private database. It then merges and formats the data into beautiful, on demand, exportable performance reports.