AWS SageMaker Algorithms
Linear Learner
Linear Learner is a supervised learning algorithm that is used to fit a line to the training data.
It could be used for both classification and regression tasks as follows:
- Regression: output contains continuous numeric values
- Binary classification: output label must be either 0 or 1 (linear threshold function is used)
- Multiclass classification: output labels must be from 0 to num_classes - 1
The best model optimizes either of the following:
- For regression: focus on Continuous metrics such as mean square error, root mean squared error, cross entropy loss, absolute error
- For classification: focus on discrete metrics such as F1 score, precision, recall or accuracy.
Pre-processing
- Ensure that data is shuffled before training
- Normalization or feature scaling is offered by Linear Learner (positive)
- Normalization or feature scaling is a critical pre-processing step to ensure that the model does not become dominated by the weight of a single feature
Training
- Linear Learner uses stochastic gradient descent to perform the training
- Select an appropriate optimization algorithm such as Adam, AdaGrad, and SGD
- Hyper-parameters, such as learning rate can be selected
- Overcome model over-fitting using L1, L2 regularization
Validation
Trained models are evaluated against a validation dataset and best model is selected based on the following metrics:
- For regression: mean square error, root mean squared error, cross entropy loss, absolute error.
- For classification: F1 score, precision, recall, or accuracy.
Linear Learner Input/Output data
Amazon SageMaker linear learner supports the following input data types:
- RecordIO-wrapped protobuf (only Float32 tensors are supported)
- Text/CSV (note: First column assumed to be the target label)
- File or Pipe mode both supported
For inference, linear learner algorithm supports the application/json, application/x-recordio-protobuf, and text/csv formats.
For regression (predictor_type='regressor'), the score is the prediction produced by the model.
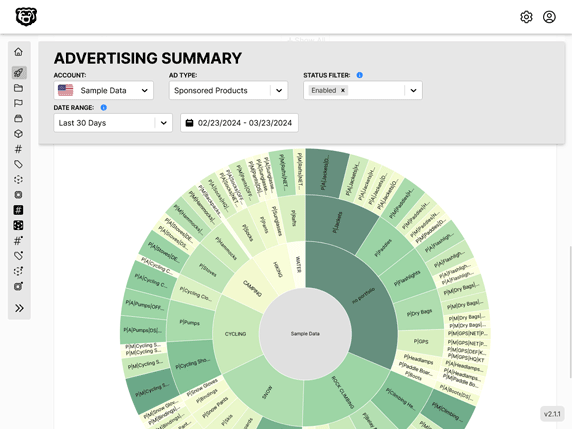
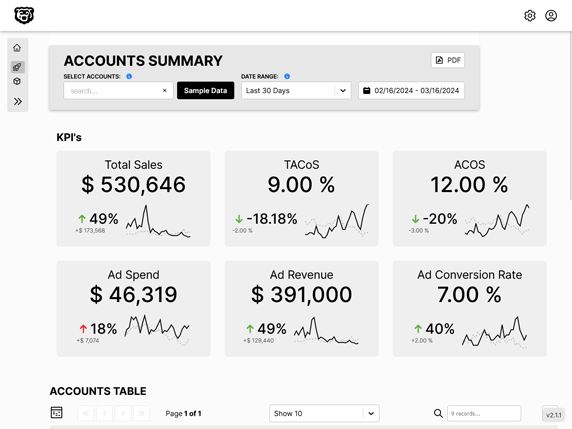
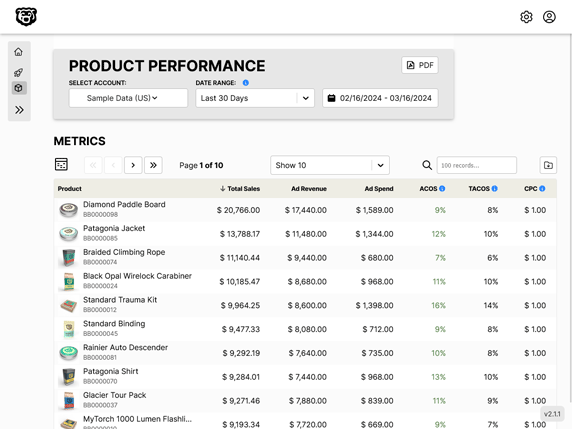
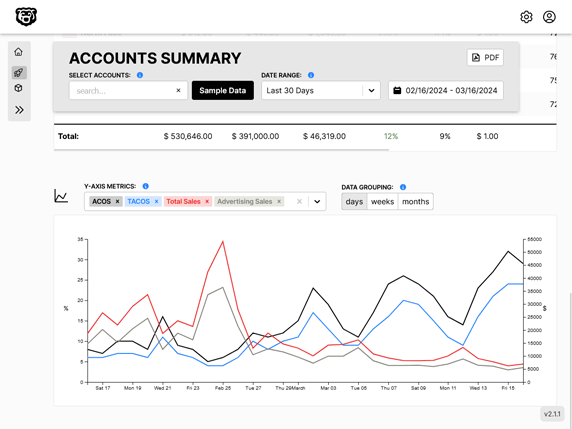
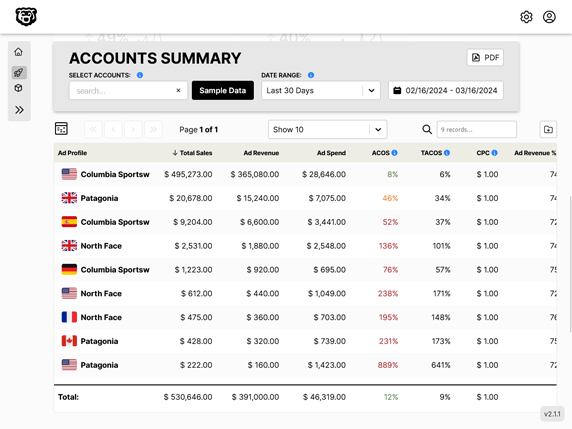
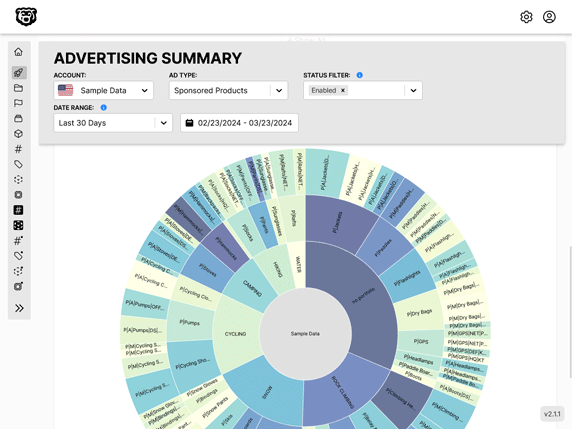
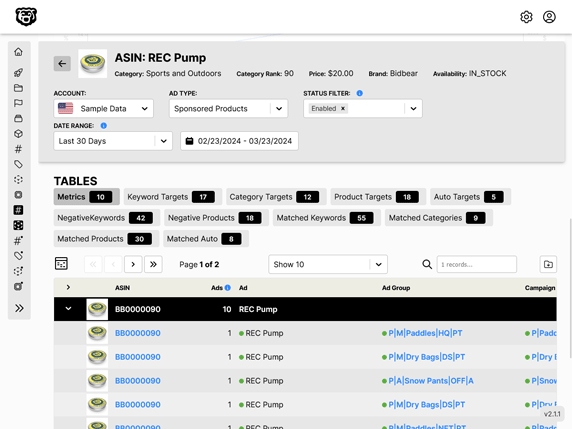
Automated Amazon Reports
Automatically download Amazon Seller and Advertising reports to a private database. View beautiful, on demand, exportable performance reports.