AWS Glue Table Repair
Intro
One of the issues that will commonly arise for me when querying Glue tables with Athena is that I will get a HIVE_PARTITION_SCHEMA_MISMATCH error. Usually what this means is that one of the columns in a data partition does not have a matching data type to the table schema.
How does something like that happen? There are many ways but here is one possible scenario. Let's say that the Glue Table is being created by a Glue Crawler, which is parsing the data types for all the columns using some set of sample data. It's possible that the initial parsing of the data types will not hold up in the future. For example if I have sales data and in the limited sample data set all the sales amounts are round integers, or zeros (EG 20 or 0). The crawler will assume that the datatype for this column is int. That will cause a HIVE_PARTITION_SCHEMA_MISMATCH error later if a new partition with a sales amount like 5.75 is added (which would be datatype double).
Unfortunately we can't simply solve this problem by running the Glue Crawler again. Let's take a look at the advanced options in the Glue Crawler.
Crawlers > Edit Crawler > Step 4: Set output and scheduling > Advanced Options
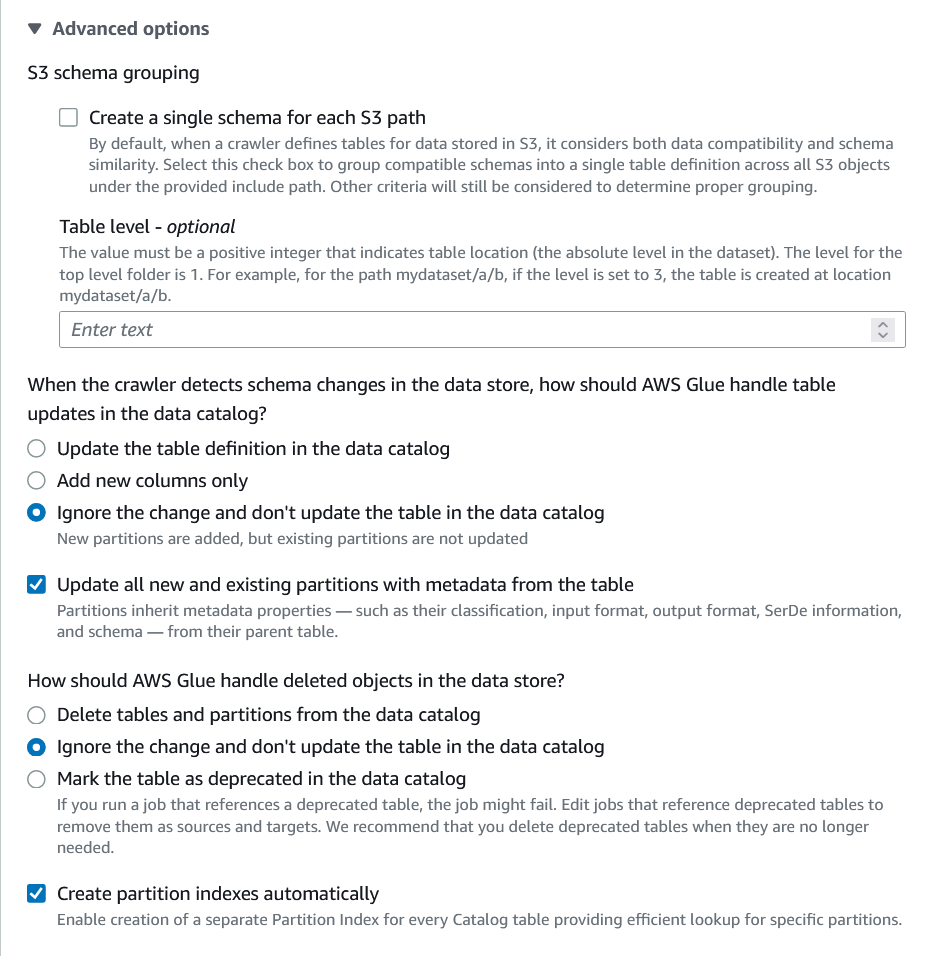
In my experience I have not had a lot of success with the "Update all new and existing partitions with metadata from the table" option. The ideal situation would be that if a partition came in with datatype double on our sales column, that would update the table definition to double, and then all the partition schemas would also be updated. In my experience it just doesn't work.
The most reliable method that I have found is to lock the table definition so that it can only be changed manually by selecting the "Ignore the change and don't update the table in the data catalog" and the "Update all new and existing partitions with metadata from the table" option together. In this way all of the incoming data partition schemas will be forced to have the same schema as the table schema, which should now be immutable unless changed manually. If the data coming in doesn't fit that schema you have a different problem entirely.
But this leaves us with the question of how to handle all the partitions that already exist in our table that don't match the schema.
The solution to this problem is to delete all the partitions and run the crawler again, which will lock all the new partitions into the correct schema.
Deleting all the partitions in a table
Remember, deleting the table partitions will not affect the actual data in any way. This is just the index of the data for the table, which can be easily recreated with another crawl run. Unfortunately there is not a very simple way to delete all the partitions through the GUI.
We have to use the SDK or the console to accomplish this. Here is the lambda function that i've written which handles this.
This is confirmed functional in Lambda running Node v16.
const AWS = require('aws-sdk');
// Set the region and initialize the Glue client
AWS.config.update({ region: 'us-east-1' });
const glue = new AWS.Glue();
exports.handler = async (event, context) => {
// Specify the database and table names
const databaseName = event.database;
const tableName = event.table;
console.log("database:", databaseName);
console.log("table:", tableName);
async function getAllPartitions(databaseName, tableName) {
let partitions = [];
let nextToken;
do {
const params = {
DatabaseName: databaseName,
TableName: tableName,
NextToken: nextToken,
};
const response = await glue.getPartitions(params).promise();
partitions = partitions.concat(response.Partitions || []);
nextToken = response.NextToken;
} while (nextToken);
return partitions;
}
try {
// Get a list of partitions for the table
const partitions = await getAllPartitions(databaseName, tableName);
console.log(`retrieved ${partitions.length} partitions`);
// Delete all partitions in batches of 25
const partitionBatches = [];
for (let i = 0; i < partitions.length; i += 25) {
partitionBatches.push(partitions.slice(i, i + 25));
}
await Promise.all(partitionBatches.map((partitionBatch) => {
let partitionValuesArray = [];
partitionBatch.forEach((partition => {
partitionValuesArray.push({ Values: partition.Values });
}));
glue.batchDeletePartition({
DatabaseName: databaseName,
TableName: tableName,
PartitionsToDelete: partitionValuesArray,
}).promise();
}));
console.log(`Deleted ${partitions.length} partitions`);
}
catch (err) {
console.error(err);
}
};
Once all of the table partitions are deleted you will have a clean slate to run the crawler again and recreate the partitions, which (if you've set the settings on your crawler as shown) will force the columns to match the schema that we have set in the table.
Automated Amazon Reports
Automatically download Amazon Seller and Advertising reports to a private database. View beautiful, on demand, exportable performance reports.