AWS Glue Notes
Intro
Glue is a microservice that catalogs data from multiple sources like DynamoDB and S3 into tables that can then have transformation jobs run on them by services like Athena or machine learning models. It can combine data from multiple different files in S3 into one comprehensive table that can then be queried in a variety of ways.
This article is not going to be a full tutorial on Glue, i'm just going to note the parts that I find particularly useful for myself so if you are looking for a full walk-through please go elsewhere.
Tables
In AWS Glue a table is similar to a table in DynamoDB except that it can actually combine the data from hundreds or thousands of different files or locations into one source as long as those sources share a common schema.
For example let's say I have an S3 bucket that gets a CSV file uploaded to it every time a customer makes a purchase at my company with the details of the purchase. There will be thousands of CSV files in that bucket that have a common schema. Glue can then combine all of that data into one table that can then be queried or transformed in a variety of ways.
You could also combine items from a variety of other databases like Redshift, MongoDB, Kafka and others.
Glue is the first step in the AWS environment to combine and organize disparate data sources for consumption by other AWS Services like Athena or Sagemaker. In fact Athena only reads from AWS Glue Data Catalogs, there is no other way to input data into the service.
Tables are organized into Databases, the tables do not have to have a similar schema to be in the same database. Databases are really sort of folders for tables, used to organize your tables into groups.
Tables can be generated manually where you create the schema yourself by hand, or they can automatically generated by crawlers. Crawlers are the 2nd most complicated thing you will do in Glue, behind python scripts.
Crawlers
Crawlers create a unified table containing all the data with matching schemas.
Crawlers can be instructed to ignore items in the folders they are crawling with a syntax almost identical to that used in a .gitignore file.
Datalake Structure
There are ways to structure a datalake in S3 that are more ideal than others for consumption by Glue Crawlers. It is important for the crawler to be able to partition your data so that it can be queried efficiently later.
📘 AWS Glue Docs: How Does a Crawler Determine When to Create Partitions?
For example at the base level of your S3 datalake file structure you should start by grouping all files with a similar schema together, and then expand to other similar elements like date and then lastly unique identifiers like user id or order number. This will allow Glue Crawlers to partition your data as efficiently as possible.
One of the useful things to note in that documentation is that we can actually name the partition automatically if we use the syntax partition=value in folder structure. For example:
S3://sales/year=2019/month=Jan/day=1
S3://sales/year=2019/month=Jan/day=2
S3://sales/year=2019/month=Feb/day=1
S3://sales/year=2019/month=Feb/day=2
will automatically generate the partitions year, month and day. It's also nice to note that we can apparently have as many sort keys as we would like (or at least more than two, which is the limit in DynamoDB without generating additional indexes).
Note that this doesn't actually seem like a good date format to use, I would strongly recommend using something like YYYYMMDD if you can help it
Bookmarks
Bookmarks are a Glue feature available in both Jobs and Crawlers that allow the Glue to only crawl or transform the files that have changed since the last action. This is an extremely useful, even necessary feature. If bookmarks are not enabled then a crawler will crawl all the files in a given location every time the crawler runs, which as the datalake grows will take longer and longer to perform. Not only are we duplicating effort, we are taking unnecessary time and cost to perform the same index or transform over and over. Always use bookmarks if your datalake is going to be growing over time.
One of the useful things to understand about bookmarks is that they function by looking at the last modified date of a file. This is useful to understand because if I want to know if I delete a file, and replace it with another file in the exact same location with the same name, will new file get crawled? The answer is yes it will, because the bookmarks use last modified and not the file name to keep track of the files that have been updated.
Jobs
Jobs are transformations, such as mapping or dropping fields, converting to another format or even just decompressing files. There is lots of information this out there. Some things to note:
- If a job is set to output a file in an S3 bucket folder, and the folder does not exist, the job will create the folder.
Job Bookmarks
Job bookmarks are one of the key features of any job, and it is vitally important to understand how they work. I would recommend reading through the bookmark documentation very closely.
Job Bookmark State
This will save you a LOT of headaches in the future. For example, it is incredibly important to know what pieces of state the bookmark is actually tracking. The documentation says (somewhat vaguely) "A job bookmark is composed of the states for various elements of jobs, such as sources, transformations, and targets. For example, your ETL job might read new partitions in an Amazon S3 file. AWS Glue tracks which partitions the job has processed successfully to prevent duplicate processing and duplicate data in the job's target data store."
However a bit later in the documentation they are a bit more specific "For Amazon S3 input sources, AWS Glue job bookmarks check the last modified time of the objects to verify which objects need to be reprocessed. If your input source data has been modified since your last job run, the files are reprocessed when you run the job again."
This is much more useful information. If you are transforming data sources in S3 the bookmark is based on the last modified date of the file. So it behaves in the same manner as a crawler bookmark.
Disabling/Pausing Job Bookmarks
Job bookmarks can be temporarily disabled, or paused. The documentation skims over these options but they are very different and important to understand.
For the following scenarios let's say that I have 100 files, each representing sales data from a specific day. They are located in an S3 bucket which we will call A. I have a job that transforms them and places them in another S3 bucket which we will call B. The job is to transform 100 files from A => B. This job has run once a day for the past 100 days.
If you disable the bookmark, the bookmark is not deleted or reset. For example let's say that I want to completely reprocess all of my data from A => B. If you disable the bookmark, you must be sure to delete all of the data in B, or else you will be creating duplicate records when you run the job. So you can write a function that deletes everything in B, and have that function in a Lambda to use at your convenience.
So you delete everything in B, run the job and then re-enable the bookmark. As long as you have not modified the files in A, the bookmark will pick right back up and only process day 101 on the next run.
What if I only want to re-process data from days 50-60? This is where the pause option comes in, it allows you to select job-bookmark-from and job-bookmark-to and in those options we would place the run id's which correspond with the dates for days 50-60. Running the job will re-process the data from those days. You must also manually delete the files in B for days 50-60 beforehand to prevent duplicate data.
Resetting Bookmarks
What if we have made a big mess out of everything? Or the bookmarks don't seem to be behaving appropriately. There are two methods to completely reset a glue job bookmark. The first is to delete the job and create another. No thank you.
The second is with the AWS CLI
aws glue reset-job-bookmark --job-name my-job-name
Just like disabling the bookmark we must remember to delete all the data in location B before we run the job again.
Workflows
Workflows allow you to string together several Crawlers and Jobs using triggers which will fire when the previous step (or steps) are complete.
There are some limitations however, here are some things to keep in mind.
Max Crawlers Per Action
A Workflow action cannot trigger more than two Crawlers at a time. So if you are trying to trigger a large number of Crawlers simultaneously you will want to use something like Step Functions.
Workflow Has Reached Max Concurrency Error
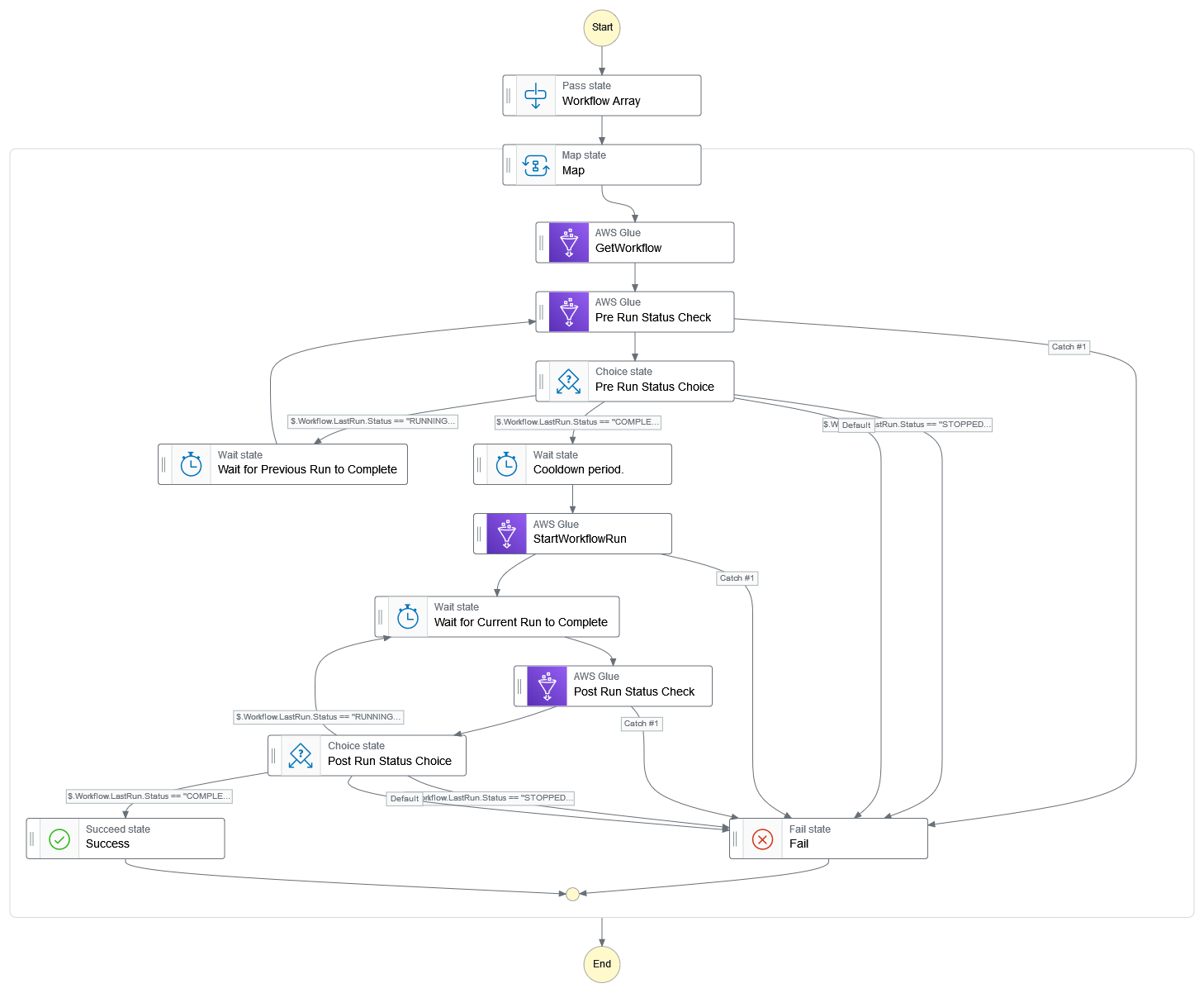
There is a known bug with WorkFlows and Jobs that have the "STOPPED" status, and which also have max concurrency set to 1. If you attempt to start a Workflow with these two circumstances you will get a Workflow has reached max concurrency even though the Workflow or Job is not running any instances. This is a known bug and has been known for at least 8 months as of this writing and it's still not fixed. The recommended fix is to set the max concurrency to two or higher. However this creates another issue, as multiple instances of a Job or Workflow running concurrently can break the bookmark feature, which is a big problem. The way that I have handled this is to set the maximum concurrency to two, and then when I trigger my Workflows using Step Functions I check the status of the Workflow first to make sure that it is not already running. If it is running (or stopping) the state machine goes into a wait loop until the current run is done. In this way there can only ever be one instance of the Workflow running, essentially manually setting the max concurrency to one.
Glue Databrew
Glue Databrew provides a really nice UI interface where you can create jobs to transform data from data catalogs or other sources. There are some features that are missing right now that would make this really useful. For example the jobs and recipes that you create in databrew cannot be added to Glue workflows, can not be exported as Python to be used in a Glue Studio custom transform, and do not appear to be able to use bookmarks.
So they are really useful for a one time cleanup of a dataset, however if you are trying to include them into an automated workflow it gets much trickier.
The only way that I could see to use them right now in an automated workflow would be to have a Step Function orchestrate the following.
- Glue crawler or job place the incoming files in a designated temporary S3 bucket
- Trigger the Glue DataBrew job to process the files in that bucket
- Trigger another standard Glue Workflow/Job/Crawler to move the files to the transformed data repository
- Go back and delete the files from the temporary bucket/folder with another Step Function step.
In this way you could sidestep the bookmark issue and Glue integration by handling everything with Step Functions.
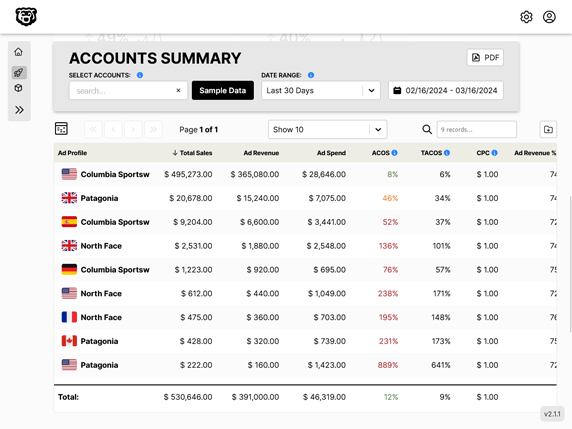
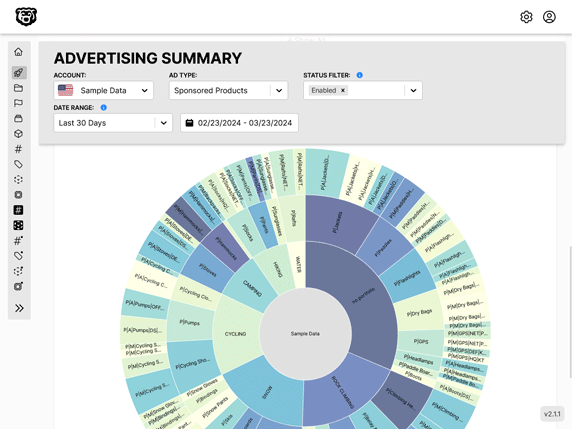
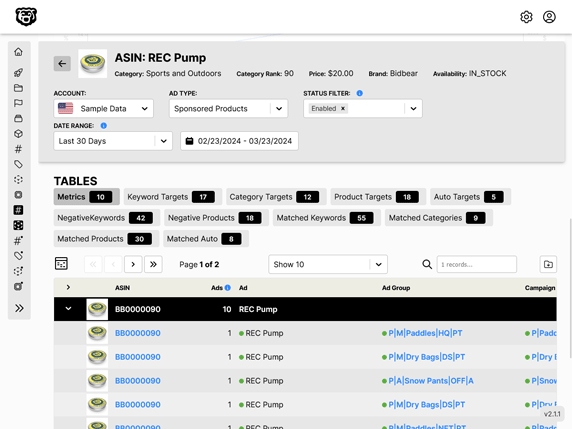
Automated Amazon Reports
Automatically download Amazon Seller and Advertising reports to a private database. View beautiful, on demand, exportable performance reports.