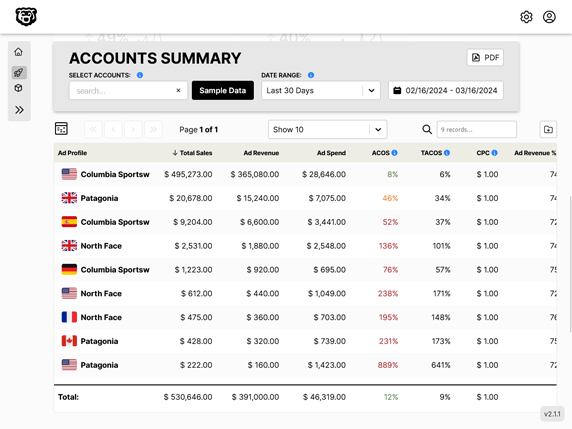
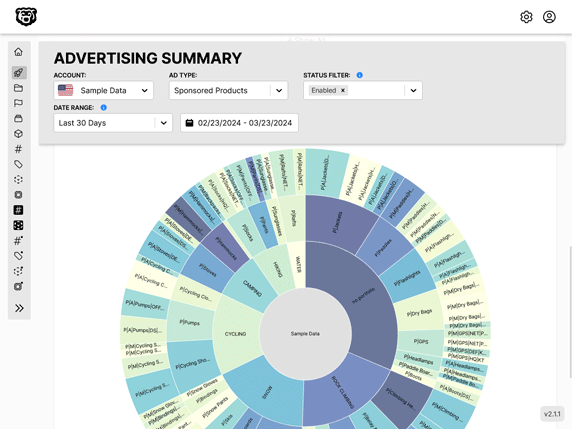
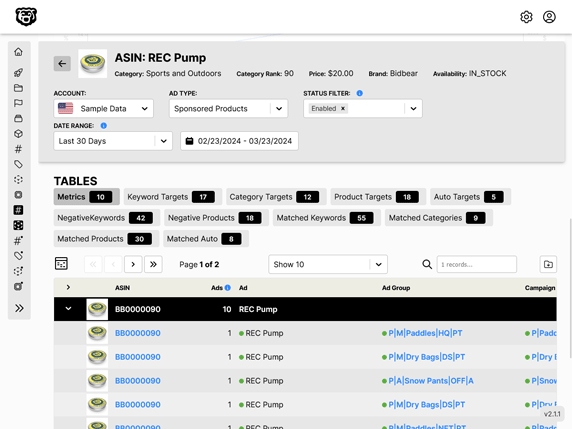
Lightning Fast Automated Glue Partition Updates
Intro
Here is a very common scenario. We have a datalake of files being stored in S3. Those files have been crawled using Glue into tables, which we can then query with Athena. Extremely common pattern. As new files are added to S3, the Glue Crawler must be run again to update the partition list before the data can be queried in Athena. However one of the downsides of this pattern is that Glue Crawlers are slow. Even if you have only added a couple of files, and are using an incremental crawl, or crawling using SQS events, the fastest time for a crawl I have ever seen is around 5 minutes. In most scenarios that's fine... but what if we need to update our partitions must faster than that? What if I told you that you could update your partitions almost instantaneously as files are added to S3? Let me show you how.
Glue Crawlers
Before we start let's just be very clear about what Glue Crawlers are, and what they are doing for us. Glue Crawlers have two primary jobs.
- Detecting schemas and schema changes
- Detecting partitions and generating partition records
The schema is the format of the data. For example there is a column titled "States" and the data in that column is in the format "string" etc etc. The first time you run a crawler it will attempt to automatically detect all the columns and data-types and compile that information into a schema.
Partitions are the map of what partition keys are associated with a file, and where that file is located. A common partition key would be a date, or a user id. For example given this file structure in S3:
S3://BUCKET-NAME/census-data/user_id=123456/date=20230124
We have two partition keys, user_id and date.
So given the following files:
- S3://BUCKET-NAME/census-data/user_id=123456/date=20230124/report.json
- S3://BUCKET-NAME/census-data/user_id=123456/date=20230123/report.json
- S3://BUCKET-NAME/census-data/user_id=123456/date=20230122/report.json
- S3://BUCKET-NAME/census-data/user_id=123456/date=20230121/report.json
If I made an Athena search to sum all the report data for user = 123456 there should be 4 matching partitions, and Athena will sum the report data of those 4 files.
If I made an Athena search to sum all the report data for user = 123456 where date is between 20230124 and 20230123 there should be two matching partitions and Athena will sum the report data of those two files.
A Glue partition record tells Athena, there is a file with these partition keys, and it is located here (s3 location). The trick though is that if you add new files to S3, it does not automatically create a new partition record, and so Athena is not aware of those new files.
Typically updating these partition records is handled by Glue Crawlers. In this tutorial however, we are going to show you how to manually create new partition records so that a crawler does not have to be run for Athena to recognize them.
Process Overview
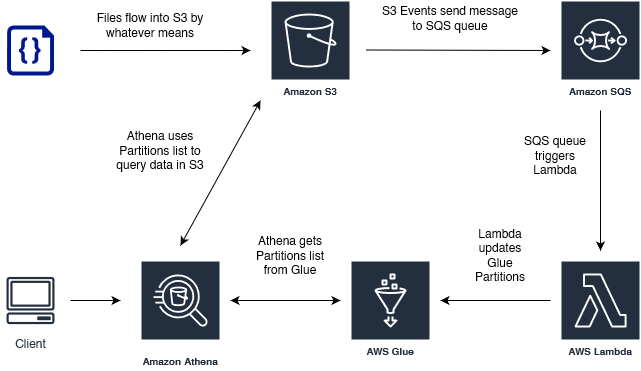
Sending S3 Events to SQS Queue
The first step is to set up event notifications on the S3 bucket that has your files. Navigate to Bucket > Properties > Event Notifications. From there you will be given the option to send notifications of changes to SQS/SNS/Lambda.
In theory we could send the notifications directly to Lambda and cut out the SQS step, however going through SQS leaves open the possibility of using the events list in a Glue Crawler, should you later decide to go that route. That whole process is described in the AWS docs here:
AWS: Accelerating crawls using Amazon S3 event notifications
That article does a great job explaining how to set up the S3 event notifications and IAM permissions for SQS, but you should note a couple of things.
- Even if you use S3 events in a Glue Crawler, it will still take several minutes (5ish) for even a few files
- The S3 events do not trigger the crawl. You will still have to trigger the crawl either manually or with other events.
That event terminology here is a bit confusing. You have to understand that the S3 change events are getting put into a queue, which will be consumed by the Glue Crawler when it is triggered (in the linked example). But you will still need a separate event to trigger the crawler, for the S3 change events to be consumed from the queue.
Processing Events in Lambda
Once you have successfully set up SQS to stack up change events in S3 (you can test this easily by adding or removing files and then checking the "messages available" count in SQS) it is time to send those messages to Lambda. Navigate to SQS Queue > Lambda Triggers. Point the queue towards a Lambda that has IAM permissions for both SQS and Glue. Then you will create your own version of the following code.
// This function is triggered by SQS queues which contain lists of updated files
// Intended to be much faster at updating partitions than Glue Crawlers, which take
// >5 minutes, even when only crawling files given by SQS queue
const AWS = require("aws-sdk");
const glue = new AWS.Glue({ apiVersion: "2017-03-31" });
let StorageDescriptor;
exports.handler = async (event, context) => {
// console.log("event:", event);
console.log("SQS RECORD COUNT: ", event.Records.length);
// SQS records may contain more than one record per message
for (let i = 0; i < event.Records.length; i++) {
// body in record will be stringified, must be parsed
let JSONbody = JSON.parse(event.Records[i].body);
// handle test events so they don't throw error
if (JSONbody.Event === "s3:TestEvent") {
return "exiting due to test event";
}
let bodyRecords = JSONbody.Records;
//console.log("bodyRecords:", JSON.stringify(bodyRecords));
console.log("S3 RECORD COUNT: ", bodyRecords.length);
// S3 records should always contain 1...
// but loop just in case
for (let i = 0; i < bodyRecords.length; i++) {
let dbName = "YOUR GLUE DATABASE NAME"; // highlight-line
let s3NotificationName = bodyRecords[i].s3.configurationId;
//console.log("S3 Notification Name", s3NotificationName);
let tableName;
// in this example our database has multiple tables and S3 event notifications for each table
// we can determine the table name based on which S3 event notification sent the message
switch (s3NotificationName) {
case "s3-folder1_PARTITION_UPDATE_NOTIFICATION":
tableName = "folder1";
break;
case "s3-folder2_PARTITION_UPDATE_NOTIFICATION":
tableName = "folder2";
break;
case "s3-folder3_PARTITION_UPDATE_NOTIFICATION":
tableName = "folder3";
break;
default:
context.fail(
`Unable to determine table name given S3 Notification Name: ${s3NotificationName}`
);
}
console.log("TABLE NAME: ", tableName);
// always fetch StorageDescriptor incase table changes
({
Table: { StorageDescriptor },
} = await glue
.getTable({
DatabaseName: dbName,
// table name
Name: tableName,
})
.promise());
const generatePartitionValuesFromS3ObjectKey = (s3ObjectKey) => {
// you will modify this function to manipulate the s3ObjectKey string
// as needed for you to extract the partition key values
// expected output for a table partitioned with user_id and date would be
// values = ['some_user_id', 'some_date']
// IE values = ['123456', '20230124']
return values;
};
let Values = generatePartitionValuesFromS3ObjectKey(
bodyRecords[i].s3.object.key
);
// using the data provided in the message, generate the location of the file
// if it is not directly available
// note trailing /
let FileLocation = `${StorageDescriptor.Location}user_id=${Values[0]}/date=${Values[1]}/`;
console.log("VALUES", Values);
console.log("FILE LOCATION", FileLocation);
// Depending on the S3 Event that we receive, we can either add or delete a partition
// if file added
if (bodyRecords[i].eventName === "ObjectCreated:Put") {
console.log("FILE CREATION DETECTED");
try {
// get partition
let result = await glue
.getPartition({
DatabaseName: dbName,
TableName: tableName,
PartitionValues: Values,
})
.promise();
if (result) {
console.log("PARTITION ALREADY EXISTS");
}
} catch (e) {
// exception... need a new partition!
if (e.code === "EntityNotFoundException") {
let params = {
DatabaseName: dbName,
TableName: tableName,
PartitionInput: {
StorageDescriptor: {
...StorageDescriptor,
Location: FileLocation,
},
Values,
},
};
let partitionCreated = await glue.createPartition(params).promise();
if (partitionCreated) {
console.log("NEW PARTITION CREATED");
}
} else {
throw e;
}
}
}
// if file deleted
else if (bodyRecords[i].eventName === "ObjectRemoved:Delete") {
console.log("FILE DELETION DETECTED");
try {
// get partition
let result = await glue
.getPartition({
DatabaseName: dbName,
TableName: tableName,
PartitionValues: Values,
})
.promise();
//console.log("RESULT:", result);
// matching partition found, delete it
if (result) {
console.log("PARTITION FOUND");
let params = {
DatabaseName: dbName,
TableName: tableName,
PartitionValues: Values,
};
let deleted = await glue.deletePartition(params).promise();
if (deleted) {
console.log(`PARTITION DELETED`);
}
}
} catch (e) {
// exception... there is no partition to delete
if (e.code === "EntityNotFoundException") {
console.log("THERE IS NO PARTITION TO DELETE");
}
}
}
// no matching event types
else {
context.fail(`UNRECOGNIZED EVENT NAME: ${bodyRecords[i].eventName}`);
}
}
}
return {};
};
There are a couple of key things to note here.
Because the S3 event messages are relayed through SQS, which in turn sends its own messages, the structure of the incoming event is a bit messy. There is an array of "Records" within another array of "Records". That is the reason why there is a loop within a loop in the code. If you sent the messages directly from S3 to Lambda, you could simplify this a bit.
The second thing to note is that this function handles both adding and deleting partitions, depending on the type of S3 event in the message.
The Values that are fed into the PartitionInput are just the values of the partition, you don't actually have to indicate the partition key.
For example given a table that has user_id partition(0) and date partition(1) you would simply input ['123456', '20230124']. The key of the value is inferred from the order.
Lastly, the file location of the partition is very important. It is possible to successfully create a partition that points to an incorrect file location. You won't get any error messages but your Athena queries will fail. You can troubleshoot this with console logs, and also by going into Glue > Tables > Partitions > View Files to make sure the file is actually there.
Be especially wary of this if you have done your file structure as in the sample above where the file names are /user_id=123456/date=20230124 format.
Conclusions
I am absolutely loving this flow. This setup automatically detects any file changes in S3 and updates the Glue Catalog table partitions within a fraction of a second of their upload, completely automatically. No more having to manually trigger Glue Crawlers and wait. It is both faster (600x) and less expensive.
Additional Resources
A similar implementation in Python:
The basis of this implementation, with events going directly from S3 to Lambda. Does not handle partition deletion, variable tables, or file locations !== partition values:
AWSTip.com: Automatically add partitions to AWS Glue using Node/Lambda only
Relevant Official AWS Docs:
AWS Docs: Accelerating crawls using Amazon S3 event notifications
AWS Docs: Configuring a bucket for notifications (SNS topic or SQS queue)
Automated Amazon Reports
Automatically download Amazon Seller and Advertising reports to a private database. View beautiful, on demand, exportable performance reports.